Many web servers (e.g. Tomcat, Apache) dedicate a thread to every open connection. When a web request comes in, a thread is either created fresh or, if possible, dequeued from a thread pool. The thread performs some computation and I/O, and the thread scheduler puts it to sleep when it blocks for I/O or when it exceeds its quantum. This works well enough, but as more and more threads are created to handle simultaneous connections, the paradigm starts to break down: each new thread adds some overhead, and a large enough number of simultaneous connections will grind the server to a halt.
node.js is a JavaScript environment built from the ground up to use asynchronous I/O. Like other JavaScript implementations it has a single main thread. It achieves concurrency through an API that requires you to provide a callback (a closure) specifying what should happen when any I/O operation completes. Instead of using threads or blocking, node.js uses low-level event primitives to register for I/O notifications. The overhead of context switching and thread tracking is replaced by a simple queue of callbacks. As the events come in, node.js invokes the corresponding callback. The callback then carries on its work until it either begins another I/O request or completes its task, at which point node handles the next event or sleeps while waiting for a new one. Here's a simple web-based "Hello, world!" in node.js from the snap-benchmarks repository:
As you can see, all I/O operations accept a callback as their final argument. Instead of a series of calls that happen to block, we explicitly handle each case where an I/O request completes, giving us code consisting of nested callbacks.
In addition to reducing the strain placed on a system by a large number of threads, this approach also removes the need for thread synchronization - everything is happening in rapid sequence, rather than in parallel, so race conditions and deadlock are not a concern. The disadvantages are that any runaway CPU computation will hose your server (there's only one thread, after all) and that you must write your code in an extremely unnatural style to get it to work at all. The slogan of this blog used to be a famous Olin Shivers quote: "I object to doing things computers can do" - and explicitly handling I/O responses certainly falls into the category of Things a Computer Should Do.
Anyway, this got me thinking about how Haskell could take advantage of the asynchronous I/O paradigm. I was delighted to find that others were thinking the same thing. As it happens, the new I/O manager in GHC 7 uses async I/O behind the scenes - so your existing code with blocking calls automatically takes advantage of the better scalability of asynchronous I/O. The Snap framework has published benchmarks that show it handling about 150% more requests per second than node.js:
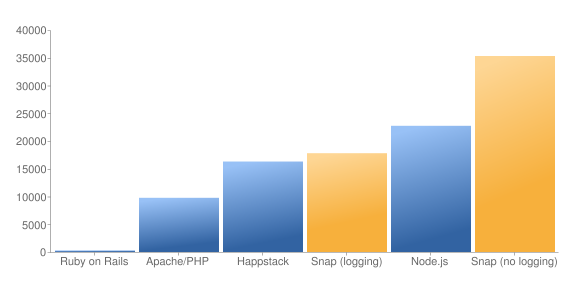
But what's even nicer is that there's no need to contort your code to get this performance. Snap and the underlying GHC I/O manager completely abstract away the asynchronous nature of what I'm doing. I don't need to set callbacks because the I/O manager is handling that under the covers. I pretend I'm using blocking I/O and the I/O manager takes care of everything else. I get some defense against long-running computations (because more than one thread is processing the incoming events) and, most importantly, I can write code in what I consider a saner style.
The catch is that most I/O libraries are not designed for asynchronous I/O. So, network and other I/O calls made at the Haskell level will work appropriately, but external libraries (say, MySQL) are often written with blocking I/O at the C level, which can negate some of the scalability gains from asynchronous I/O.
The same could be said for Erlang. The way I see it, Node.js is not providing us with a sane programming model however it brings high-scalability in the real world. Other languages must follow. Node.js is increasing the pressure.
ReplyDeleteI've worked with asynchronous framework for a while. Based on my experience, I found that when multiple asynchronous calls are involved in handled one user request, it's a mess. Callbacks after callbacks make it's difficult to see the business process by reading the code. So I agree gawi that Node.js is not providing us with a sane programming model however it brings high-scalability.
ReplyDeleteYou're absolutely right in that external libraries which make blocking calls can negate some of the gains. The beauty of the GHC I/O manager design is that we can still use those libraries. In most async frameworks you need to rewrite every single library that makes blocking system calls to work with the framework, otherwise the event dispatch thread will get blocked. In GHC you can do so only when you need to due to performance reasons. The way GHC manages this feat is by having a small (dynamically resized) thread pool per core that gets used for blocking calls.
ReplyDeleteIn that case, Warp should be even faster, according to these benchmarks:
ReplyDeletehttp://docs.yesodweb.com/blog/announcing-warp/
The GHC IO manager was always async, the new one just uses epoll instead of select.
ReplyDeleteI took a hard look at Node.JS, while I don't think it will be the next big thing I think they did break some new ground on a few points and that is useful.
ReplyDeleteI also think it is useful to every so often say "hey lets try something different and see if it works better". And of course you don't know if it will until you try it for a while.
To Peter and Bill,
ReplyDeleteSince events and threads are dual, it trivial to get a cooperative multithreading environment built on top of node.js.
To do this, systematically CPS transform your code. You don't have to CPS transform every little thing. You just need to pass in the continuation as the callback to the asynchronous calls, and any function that does this is itself asynchronous. From the perspective of the cooperative multithreading system, the asynchronous calls are the blocking calls. I recommend using a monad to handle this CPS transforming, but that is not necessary.
Now all you need is forking and perhaps synchronization. The fork operation simply adds its argument to a ready queue. Now you simply wrap all the (primitive) asynchronous calls with a function that registers that passed in continuation and then dequeues a new continuation from the ready queue and executes that, or, if the ready queue is empty, it returns to node.js. Since this is a cooperative system, you'll likely need a yield operation which would clearly be "blocking". There are at least two that you'd want. A "soft" one simply enqueues the continuation its given and dequeues a new one. A "hard" one which registers its continuation as an "on idle" or "on timeout" event handler. MVars or channels are easy to implement in this context.
The fact that Javascript doesn't guarantee TCO is not a big problem here. As long as you make a "blocking" call in every loop, using yield if necessary, the stack growth will be bounded. Compute-intensive workloads will need to have yields sprinkled to guarantee responsiveness.
This is more or less what GHC is doing where the calls to yield are in the memory allocator. As this and GHC demonstrate, there is nothing inherently faster (or slower) about using events rather than threads.